I have been reflecting a lot on this and I think it is time to share some thoughts here. I want to talk about what I perceive to be interconnected phenomena. This also discusses the role of the researcher and I am speaking here as a relatively sophisticated user of AI technology, having very closely tracked its evolution since my childhood and youth, alongside the internet.
I want to talk about the topologies of research in the social sciences, and in economics in particular, and then provide an outlook. The article also interweaves a few dimensions to highlight the links to geopolitics. The core argument is this: we already have a misallocation problem in how research effort gets allocated across backward-looking and forward-looking work, and AI is now entering precisely into that misallocation. This creates new opportunities, but it also sharpens an older question, namely what assumptions we hold about how knowledge is used in society.
Backward looking research, the bread and butter of research in social sciences
In my journey as an academic, I was always a bit frustrated that most of what we do as economists is backward looking storytelling. In some way, it is sensible. We look back in time to write a paper to explore or explain a phenomenon where the ex-post rationalization may resonate with many people. This is often how social science accumulates understanding, and in good cases, it works very well.
Careful empirical research in economics, I think, offers what is de-facto a zero-knowledge proof. I feel that elegant papers are designed such that they offer so many angles and avenues, along with appealing to human intuition and basic knowledge, that the conclusions become close to undeniable even though a small residual of doubt may exist. That is, it is a probabilistic proof. This, of course, does not imply that a narrative that is spun around a set of nested findings is “correct” (though there are often uncountably many stories, meaning temporal consistency is a key validator), but it may help rule out and make salient specific dimensions. So the strength of the research result and the strength of the story wrapped around it are related, but they are not the same thing.
Our publishing system, by virtue of the perceived need to maintain the authority of an outlet’s reputation, then naturally skews towards publishing work where it is perceived that a narrative or a story has, ex-post, proved broadly correct. And for this, time is a vital factor. Only time can tell which narratives dominate in the popular discourse. This is what generates attention and may reinforce the perceived authority of academic publishing. The delays in academic publishing may thus become an important production factor and in some ways publication then mostly becomes a type of certification, not so much a process that actually shapes frontier narratives. Put differently, publication often arrives after the narrative frontier has already moved, and its role is to certify what has aged well.
And, of course, given limitations to processing of information, and the need for dimensionality reduction in an information rich but attention scarce world, shaping stories or narratives is a main vector of social influence. The dominance of some journals, in particular those from the US and Europe, may create a perception issue as it may reinforce schools of thought, or rather some ideological foundations, rather than objective values. This is one source of skew in the system, and it matters because it conditions what later counts as legitimate knowledge.
With generative AI, many things are changing, and invariably it will potentially lift publishing into the 21st century. This may mean that we all may become validators. This is even more relevant if more and more government is run on natural or actual experiments. That is, reviewing may morph from being the ugly unloved (sister|brother) of academic publishing to its full equivalent that may offer similar perceived status reward as top publications presently appear to do. We may all morph into validators and auditors of knowledge traces, because that is what we can still do and this is where the value lies. Think of it as becoming community-sponsored investigators. This may undo some of the historic skew that has been introduced with the internet and the skewing in the perceived returns to academic work. I will return to this, because this is one of the important margins on which AI changes the game.
This may have been particularly problematic for Western academic tradition that supports and encourages genuine curiosity-led research. Curiosity led research that chases attention rewards can get hacked through media-agenda setting. It can lead generations astray and contribute to producing academically vetted disinformation. Yet, I fear that the shifts in how academia functions in a digitally connected world may have unintended consequences here. Given perceived and actual insecurity in academic labor markets, research focus and attention may be quick to skew.
And so, answering questions that few people may care about intrinsically, while being the ultimate risk taking activity, may become collateral damage. It can create hordes of researchers chasing epistemic rabbit holes for concern about recognition and publication. This is reinforced by the fact that academic publishers and universities are interested in impact and visibility, and most university rankings are in essence a popularity contests. So even before AI, we already have a system that under-rewards validation and over-rewards visibility.
From this perspective you can easily understand the attractiveness of near-time or forward looking research.
Forward looking research, or the perception of low hanging fruits of attention
Unlike backward looking research, near-time research around new phenomena or sharp policy or narrative shifts is invariably drawing attention. I am thinking here of the many forms of trackers, real-time surveys and the like. I have done quite a bit of work in this area myself, simply because I felt it was important to work on said topics and, given the lack of transparency in exactly what or how policy making is invoking sharp evaluation techniques, this mattered (in the UK, this is changing now with public evaluation registries). But I also felt that policy making and transmission was at times artificially constrained and slow.
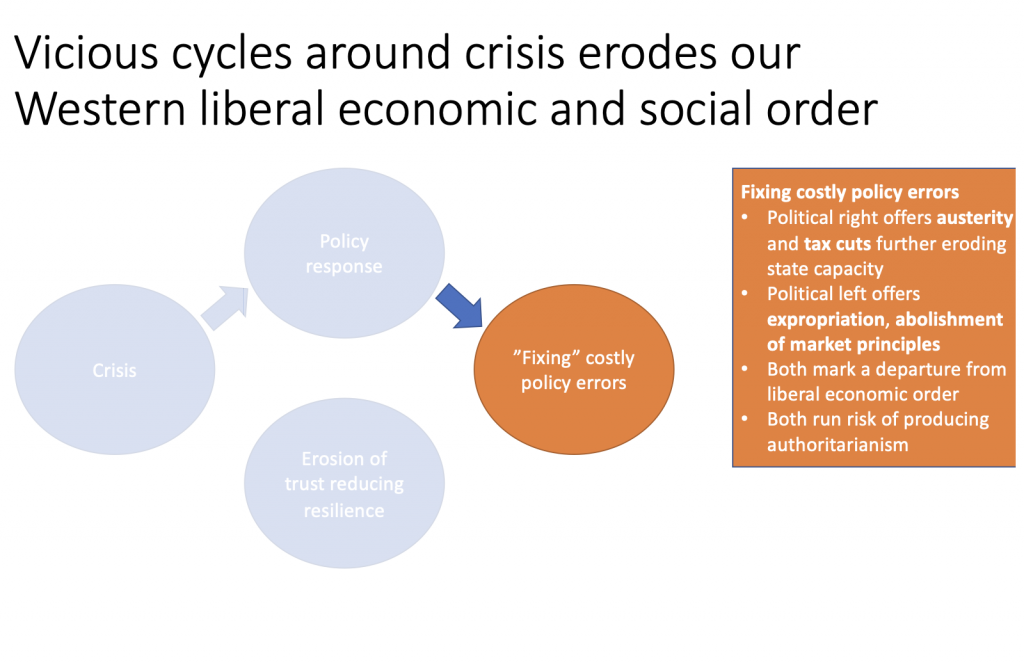
The most recent episode of this that was, in my view, fiscally quite consequential for the UK followed the energy crisis induced by the Russian invasion of Ukraine. This has enabled Putin to influence narratives that may be very powerful in the Global South, since the Global North expanded massively fossil fuel subsidies while typically preaching players in the South to reduce expensive fossil fuel subsidies. Further challenges arose with the lack of agility and speed, along with potentially challenged digital literacy, fragile IT infrastructure and possibly a lack of competencies or performative state capacity that itself may have been a product of post-2008 austerity, which became most prominently visible during the COVID-19 pandemic. I am spelling this out because it shows that fast, forward-looking research often emerges for good reasons. It is not merely opportunism; it is sometimes a response to real institutional bottlenecks.
Why attention rewards are perceived to be less risky at the frontier
But of course, there may also be an element of collective FOMO. In light of high powered incentives, few publication outlets, job insecurity and tenure pressures, working on new phenomena may be more likely to guarantee some rewards faster because demand for this work is much more certain. The reason for this demand is increasingly well understood: the human brain ultimately is a threat prediction engine and so, since the unknown may be perceived to be risky, it is not surprising that attention is skewed. “If it bleeds, it leads” is the common characterization in popular media. These biases have a huge impact on collective resource allocation and attention (see the work on media multipliers and on natural disaster-adjacent reporting). Work that is boring, or where the status rewards or publication success may be much more risky, receives notably less attention. In the SHAPER keynote and in some lectures on LLMs I have tried to make this salient.
This does open the possibility that there can be a quite inefficient allocation of resources. One way to gauge this is how there was a deluge of research on the pandemic, with tons of duplication of effort. Yet unfortunately our current publishing system has a way of then encouraging others to dress a donkey for a stallion, to upsell, rather than simply be able to publish a duplicate research paper under a thread of an anchor paper that may have made a similar claim using similar techniques. There is no perceived value in independent validation, which is a pity, because validation is so important precisely because there are many forking paths, especially in applied research. Publishing “duplicate” research could well involve the same journal, as this actually helps reinforce the authority of a claim in a way that is auditable. In other words, the system that says it cares about truth still structurally under-rewards one of truth’s most important production processes, namely replication and independent checking.
So collective FOMO in the profession is a feature, not a bug. But obviously the rewards are extremely thin and it appears to me that they are highly correlated with the perceived status of the individuals involved. This reinforces and entrenches hierarchy in the profession and may induce whole generations to pursue lines of inquiry that, counterfactually, they would not take.
So let us combine what we have so far: backward looking research with journals providing certification; forward looking research on novel phenomena that is guided by collective FOMO but offers elusive quick rewards in a context of high anxiety and sharp up-or-out incentives; and the human brain as a threat prediction engine, along with a media system that rewards novelty precisely for those reasons. This combination, I think, helps explain huge issues around misallocation of research effort, when in fact we may want to push a lot more attention to the boring and the benign, the micro interventions, the study of micro data from small institutions or organizations, and be much more creative about the engineering and the plumbing of how effective collective action may be shaped. This is the point at which AI enters the story.
Enter AI and with it, non-linear knowledge production and the possibility of complexity explosion
We are now in a situation where, with AI, we can produce knowledge much faster than the existing system can process said knowledge. This was already an issue, but it is set to get worse. We will see a tokenization and possibly a narrowing of complexity as quick wins or sugar rushes are being sought, when in fact I think complexity is precisely what we need to develop an appreciation for. So AI does not arrive into a neutral environment; it arrives into a system that already over-rewards narrative compression and under-rewards validation.
The disconnect between publishing (or certification) of knowledge and its creation may get even wider, especially if the validation layer and the rewards to that validation are not strengthened. And so may the disconnect between the imagined and the real economy, as delivering in the real and tangible economy on ideas and knowledge is simply much more complicated because you need to be doing stuff.
I am thinking here of my friends in Tanzania who are working to smartly replace synthetic fertilizer and create local value chains. This is taking the work on production networks at heart to identify pivots. This is one reason I think AI could either become a tool for rebalancing attention toward implementation and verification, or a tool that further accelerates symbolic production, while leaving the hard work of institutional and material transformation behind.
But there is also another dimension. Knowledge creation, precisely because it is hard to keep up with it, may all of a sudden become a source of anxiety and fear.
How so? Is knowledge power? If you subscribe to the assertion that knowledge is power, then you are also sensitive to the idea that this power may be exercised on humans in ways where there may be broad debate about what is ethical. This is where the argument shifts from research production to the social uses of knowledge.
Data and evidence abound that research findings have been used not necessarily for the betterment of the human condition, but also for coercion and submission, for violence. If you exhibit traits that suggest certain cognitive limitations, for example around statistical reasoning, gambling preys on this. Humans crave easy calories (think sugar), and this may create addictions and huge public health externalities around obesity.
Tobacco interests provide an incredibly addictive substance, nicotine. The list extends very long. But the past 20 years have also seen an explosion of our knowledge around behavioral biases and skews, and it is hard to see how such knowledge may not, given system incentives, produce outcomes where many people simply feel they are getting screwed. My friend Eric Lonergan has summarized this sentiment in his book on Angrynomics.
People may not be able to pinpoint the blame in any way that is sharp, but they would be angry as they may perceive they cannot get ahead in life. And again, it is only a select few who may know how to protect themselves. That anger makes itself felt across societies and communities, and that anger is channeled by narrative merchants and their acolytes. The populists are mastering this art as I tried to highlight in this work on narrative linkage around the Brexit referendum in the UK most appropriately summarized in this thread.
But the process is self-defeating. People do not feel like they get ahead in life, and so they give up or disengage. They do not have children. They do not reproduce. They do not do what at some times may have been perceived as “a good life.” I believe this same logic is what induces now a whole generation to go on a demographic strike. Whether one agrees with that phrasing or not, the deeper point is that distrust in the social uses of knowledge can produce very real social and demographic consequences.
Fear of knowledge and risk to the enlightenment consensus
The human mind is now in a very tricky position, because technically, keeping up to speed with knowledge production becomes ever more difficult. Disinformation may further proliferate and sheer volumes escalate. And most importantly, if knowledge is power, how is that knowledge used in society to shape your life and mine, to shape our mutual coexistence on this planet? This becomes the central political question, not a side issue.
With non-linear increases in knowledge creation, knowledge may all of a sudden become a source of perceived threat if the ethical guardrails to its use are not sufficiently strong. This is a key point of friction with our tech bros in the United States, namely if the risk is there that the technology may effectively be used for purposes other than improving quality of life and human dignity with a shared consensus of what basic human rights look like or quite polarized views of what a “good life” looks like. This may be a threat to the enlightenment consensus and may bring a new dark age.
Enlightenment has lifted humanity upwards because it implied that a consensus toward knowledge creation and knowledge valuation had emerged. But maybe this consensus is now under threat, especially if the risk is high that knowledge, once produced, is not used to further the human condition but to further shape extractive relationships between different groups in society, to sow division and to entrench power, to coerce individual will over others, to reject freedom, and most crucially to reject the idea that humans thrive precisely when they are able to organize life in complex collectives. So the issue is not simply whether AI accelerates knowledge production; it is whether the social legitimacy of knowledge itself starts to erode.
Where to next?
To elaborate on this argument, it is imperative to note that when we live in complex societies, we invariably must have deep trust in the institutions that safeguard us from excess and from each and one of our freedom to infringe on the freedom of others. Because control of excess (and even agreement on what excess is) is beyond the means of the individual, precisely for the reason that we ask humans to specialize. So we are asked to trust technology, but this trust layer has been under repeated attacks over the many crises that, in particular, my generation and the subsequent generation have experienced.

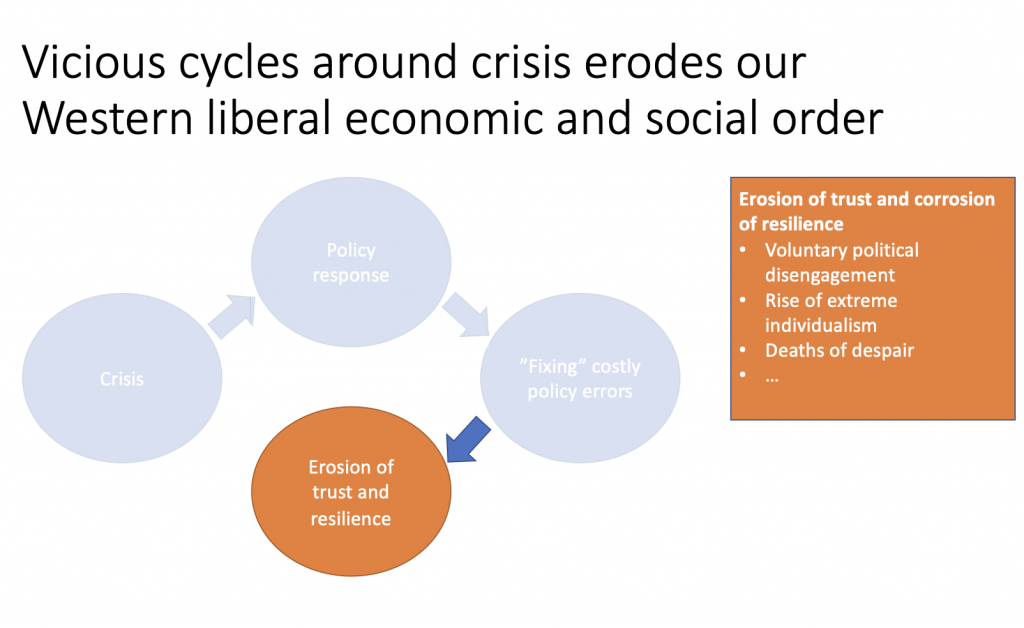
This is asking a lot, especially in a context where perceived inequality and quality of human outcomes have eroded, and where people perceive a low valuation of the future as expressed through a generation’s hesitance to bring children into this world for simple fear that they may not expect a life with dignity and in the context of the climate crisis which is scary in so many dimensions. If AI is entering into this environment, then the decisive issue is not merely model capability, but the trust architecture around how knowledge and power are used.
On the importance of the assumption layer
And this is where the assumption layer comes in and it carries a sharp geopolitical signature. Because the decisive variable is not what the models can do, but what we think the other side, and increasingly, what we think our own elites, will do with what the models make possible.
The assumption layer is the thin membrane underneath every technical argument: the prior you carry about intent. Do we believe knowledge will be used to heal, coordinate, and enlarge human freedom, or do we believe it will be used to profile, corner, and manage people into compliance? You can have the same capability frontier and two radically different social outcomes, simply because the assumed intent differs.
And here is the unsettling part: once that layer is contaminated, “let’s just see what the data says” stops functioning as a stabiliser. Evidence does not land in a neutral mind. Certification does not repair a broken prior. If the default expectation becomes extraction, every claim is heard as a move in a game, every measurement as a weapon, every model as a targeting system, every institution as captured. The world becomes legible as coercion, even when it is not. And then it becomes coercion, because everyone starts acting as if it is.
If we assume that everybody only looks out for themselves, we drift into an equilibrium where it is rational to treat this technology as an instrument for mind control, suppression, coercion, and extraction, and where it is rational to build the surrounding architecture accordingly. Crucially: if you believe there exist actors willing to use it this way, you start behaving as if you must pre-empt them. You harden, and close and you may reduce the circle of care. You normalise surveillance as “defence” and at that point the anxiety is not irrational, it is a logical consequence of the equilibrium you think you are already in.
In a world where intent is assumed hostile, capability becomes indistinguishable from threat. The mere possibility of cognitive targeting gets treated as an inevitability. And once states and factions internalise that logic, escalation happens even without a single “smoking gun” event — because the fear is about what could be done, invisibly, at scale, and with plausible deniability.
This is also why selection into power matters so much. If the conveyor belt into our social and political hierarchy systematically rewards certain traits, ruthlessness, status hunger, comfort with instrumentalizing others, then the assumption layer shifts endogenously. People begin to expect brutishness because brutishness is what the system appears to select for. Extreme examples, the casualness of Putin’s human churn in Ukraine, or assertions to let bodies pile in the street, matter not because they are typical, but because they make the equilibrium logic impossible to unsee.
At the frontier of knowledge, assumptions about behaviour in complex collectives become system-organising. We want statistics to guide decisions, but statistics are interpreted by humans, and humans interpret through priors about intent. I have always felt it is lazy, and often morally corrosive, to assume what is in somebody else’s mind. Yet assumptions are the cheap compression mechanism we reach for when complexity spikes. And AI is about to spike complexity everywhere.
If the dominant assumption becomes “everyone is out for themselves,” you get small circles of care, thick boundaries, and the reflex to treat “the other” as risk. Add the further assumption that the technology will be used for extraction rather than dignity, and you get a world in which coexistence becomes fragile. Distrust is no longer a mood, it becomes infrastructure. And once distrust is part of the core organizing fabric of society, it reproduces itself (and such a structure may, deep down, benefit some groups in society markedly more than others).
The point is not that distrust is irrational. The point is that distrust is self-fulfilling, and that it is precisely the assumption layer that makes it so. When extraction becomes the default expectation, cooperation starts to look like being the only fool without armour. Now, and as an aside: If you further develop this argument you will arrive at the conclusion that all of this is an existential threat to China, or, well the CCP rule.
For me, the ultimate signal about trust is still the tax system: tax compliance in democratic societies reveals a preference to both, a commitment to the idea of a social contract and to a commitment to the idea of democracy. You can dislike taxes and still understand what they represent: a baseline willingness to fund a shared capacity under democratic accountability. When that willingness collapses, it is often because the assumption layer has shifted — because people no longer believe the commons is real, only the extraction is.
To make this go full circle and connect back to the role of academics and researchers: we have historically played a role as stewards of trust. But the competitive mindset, elusive reward structures in academia, along with ever sharper narrowing of attention rewards may be a slippery slope into zero-sum thinking. Once zero-sum becomes the default assumption layer, “extraction” gets rebranded as realism, and coercive architectures get sold as pragmatism.
Now add persistent digital identity and weak privacy, which is arguably a feature of less strongly governed data security, in particular in the United States. This allows actors can link behaviour across contexts, construct profiles, and trade in inferred intent. Data brokerage supplies the raw material that is often collected and shared without what some may argue constitutes informed consent. Inference markets turn that raw material into high-resolution targeting. Microtargeting then lets persuasion run in the dark, not exposed to public contestation, not forced into shared facts, not even forced into consistent narratives. This is precisely what was, for the first time at scale, deployed around the 2016 EU Referendum and Brexit in the UK through profiling and micro-targeting allowing the same political choice (a vote to Leave the EU) being presented as an entirely different product for different audiences.
And that is the real horror: influence operations no longer need to convince you of a specific lie. They can aim lower and hit deeper, especially as marketplaces for reasoning traces proliferate. This is where psychological warfare or cognitive warfare starts. And there is a growing set of players that develop teams in this domain. They can aim at the assumption layer itself, systematically seeding the expectation that cooperation is for suckers, that institutions are rigged, that expertise is just marketing, that everyone is extracting and you are the mark. Once that belief is installed, society does the rest of the work for them.
To make this go full circle and connect back to the role of academics and researchers, we have historically played a role as stewards of trust. Yet, the competitive mindset is a slippery slope and gets you into a zero sum thinking mindset very quickly. And once that becomes the default assumption layer, it becomes much easier to normalize extraction as realism.
With persistent digital identity and weak privacy, actors can link behaviour across contexts, increasing the risk of profiling. An existing ecosystem of data brokers already sells detailed personal attributes and inferred interests, providing raw material for high-resolution targeting. In the US, such political microtargeting is already possible, enabling individualized persuasion. It can incentivize divisive “wedge” campaigning precisely because messages are not exposed to broader public contestation. This is precisely what was, for the first time at scale, deployed around the 2016 EU Referendum and Brexit in the UK.
Going full circle: the raw material of power in an AI world may necessitate a pivoted information topology
How to prevent this? The power in this new AI paradigm is in our underlying data. And the rebalancing that is needed to redistribute the power back to the data owners, may be never as important as now. But this also raises the sceptre of a geopolitical clash here is most obvious because in China, data is recognized as an asset class; in the US and Europe, information is often extracted indirectly, despite instruments like GDPR, with legalistic language that is inaccessible but allegedly creating “informed consent”, with poor and limited broad understanding of exactly what, how and where information can flow. In that line and on the geopolitics, its worth flagging up that the global governance around data flows is incredibly weak. Since 1999, there has been a moratorium on there being no tariffs on data flows. If said absence of tariffs are what enables e.g. large scale IP theft; industrial espionage and the likes, then, well, it seems that rethinking institutions in this space is highly desirable. The temporary moratorium has been kicked down the road for years on years, the US pushes for permeance, other emerging market economies oppose this.
This is a key and ongoing tension between the US and Europe in particular, and is a vulnerability that the US has, and which the US recently has weaponized due to European dependence on security assistance in the context of the Ukraine war. The EU (and others) swallowed the pill that the US are not part of the OECD accord on taxation of multinationals (with China also not making much noise here). The main concern here is one of taxation, or the current lack of ability of tax systems to encourage companies that are highly net cash generative to contribute to public good provision in a way that is subjected to democratic accountability (possibly because they have a mindset that they may provide public goods in a “better” way, which I agree they may have, but they can not sit outside the realm of democratic governance). So the issue is not only privacy or competition policy in the narrow sense, but the institutional capacity of democratic societies to govern the information layer as part of the commons.
The architecture of trust is a shared and collective, collectively stewarded resource. If societies are governed by a social contract, people need to trust that social contract, and they can exhibit their trust in that social contract through contributing to the commons, not evading taxes, just being good citizens. And if one dislikes some forms of taxation, it is important that they feel empowered to seek recourse and seek representation. And this most importantly requires democratic societies to morph much closer to the version of democracy that is lived reality in Switzerland than, let us say, the US or the UK.
I am not sure if wealth taxes are per se the best instrument here, but I am not unsympathetic. Yet, what most folks do not realize is that cash versus wealth are two separate things, and the US is full of broke millionaires that have a ton of wealth, but if they were to start liquidating it, that belief system would collapse quite fast. That is, the wealth is on quite shaky foundations and AI is definitely doing a lot of shaking here. In fact, I feel its hollowing out US advantage, especially if paired with instruments like CBAM. The winners here are obvious to predict. Recent dislocations in some markets point in that direction. I mention this because AI is not only a knowledge shock, it is also a valuation shock, and that feeds back into trust and political conflict.
I do think that the information layer, the trust architecture, is a public good, not a private good, not credit scoring, not proprietary black boxes, but something where doing due diligence becomes easy. I was always very amazed by how the UK was quite well ahead here, but the absence of ID verification etc made it very easy for this openness to be abused. But technically, it is now very easy to see if a person who has been conferred with community trust, did not cheat? In the linked twitter post I highlight how this may work. That is the vital architecture of what trust would look like.
Right now, it strikes me that a lot of the informational plumbing is almost an accidental construct made possible due to oversharing of data that then may get merged or combined in ways that may, not always, come with the explicit consent of the data owners. Moving to a new equilibrium of sharing (immutable) derived knowledge, not underlying micro data, strikes me as a way to maintain benefits of relatively free flows of information, but it vastly may significantly rebalance power in data and information markets and may also undermine security architectures in places and, well, requires a drastic change to the informational plumbing of societies. You can easily see how this may be problematic for some players more than for others (in essence US focus on information intermediation…), and it may also imply that if we move to an equilibrium with less information sharing and less meta data collection or, more privacy, this may undermine security postures. This may mean some geopolitical players may now be forced to move aggressively before their technological window closes as demands for privacy increase.
But, in order to make capitalism work across the globe, we need trust. If you want climate action to happen, we need to establish ways of engineering and creating capital flows and that is easiest where the trust layer is one that is auditable. To reduce the cost of allocating capital to developing countries.
I think universities and their respective alumni networks may be absolutely vital here, but even more is the need to establish good quality public data infrastructure. This is where the earlier discussion about research topologies comes back in: if AI cheapens some forms of novelty and makes validation more central, then universities and public institutions have a chance to reclaim a role as validators and stewards of auditable trust.
At the frontier of knowledge, the real question is not technical. It is what governs interpersonal behavior. If we assume extraction, we get extraction. If we assume cooperation, we might get coexistence.
Given the current technological possibilities, and given poor information governance, it may be possible to engineer an outcome whereby the assumption is extraction, precisely for the reasons outlined above — that humans in essence, become hackable.
To allow the possibility of self-determination, only radical (self) sovereignty can be the answer and this invariably will require a radical privacy pivot and a shift to an inverted data ownership topology whereby data sharing is limited, but knowledge sharing is maximal. I have a hard time seeing how this is the outcome that the tech companies are steering us towards.