I wanted to share a longer reflection on reasoning models, because I think a lot of the public conversation around AI capabilities is still framed in a way that is slightly misleading. I have circled around this in earlier notes on human embeddings, AI, human cognition and knowledge collapse, and the topology of knowledge creation. We tend to talk about models as if they are simply becoming "smarter" in some generic sense, or as if the main story is more compute, more data, larger context windows, and more parameters. Of course all of that matters. But it misses something that, to me, is becoming increasingly central: these systems are not only learning language. They are learning solution paths.
This is a non-technical attempt to explain what I mean by that. The figures below are deliberately stylized. They are not meant to describe the literal architecture of a frontier model. They are meant to make visible a mechanism that is otherwise quite hard to see: when millions of people interact with AI systems, they do not only produce outputs. They also reveal how problems are transformed into solutions. They reveal the start point, the failed detours, the edits, the constraints, the final fixed point, and often the user’s implicit evaluation of whether the solution worked.
That may sound like a small thing. I think it is not. It helps explain why models can seem to improve so quickly. It also changes how we should think about intellectual property, about the value of ideas relative to execution, and about the incentives to share knowledge in a world already saturated with performative activity.
The Input-Output View
Let me start with the simplest picture.
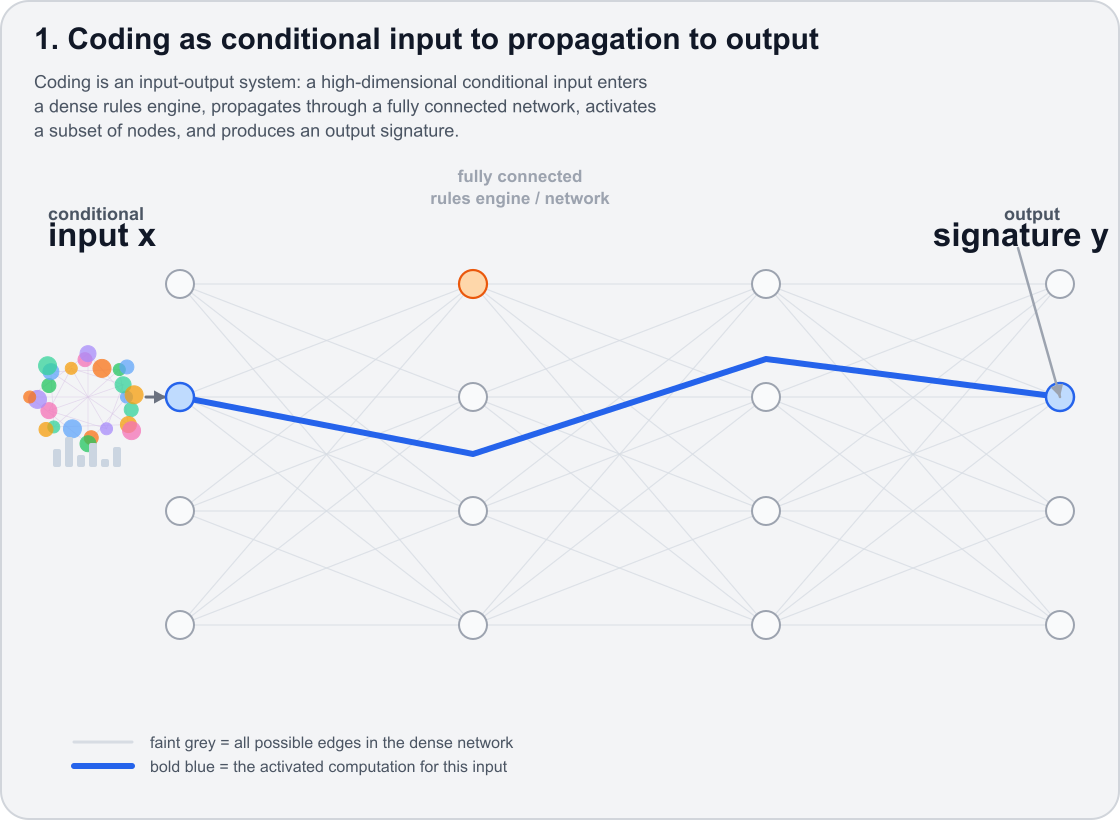
Figure 1: A stylized input-output view. A problem enters a dense rules engine, activates a path through it, and produces an output signature.
One way to think about coding, writing, analysis, or even a research workflow is as an input-output system. You start with a problem. You condition on some context. You pass that context through a dense set of rules, associations, examples, memories, tools, and constraints. Then something comes out: code, text, a table, a diagram, a decision, a diagnosis, a hypothesis.
Humans do this all the time. We often pretend that the valuable part is the final artefact: the script, the paragraph, the slide deck, the policy memo, the proof, the chart. But the final artefact is only one endpoint of a much richer process. The valuable object is often the path from the idea, to the formulation of the problem to solution. It is the chain of choices that says: given this kind of problem, in this kind of context, with this kind of constraint, this is the route that tends to work.
That route may be short or long, it may be a winded path or more direct; it may be robust or brittle. It may require domain knowledge or only pattern matching. But it is a route from problem formulation to solution. And once a route is observed often enough, it can be reused.
This is where the simple input-output picture becomes more interesting. A conversation with a model is not just a user asking for an answer. It is also a trace. The user starts somewhere, the model responds, the user corrects, the model tries again, the user adds a constraint, the model revises, and eventually the conversation stops. That stopping point is informative. It often means that the user reached a good enough fixed point.
Put differently: every interaction can reveal something about the mapping between intention and satisfactory output.
Many Paths To The Same Place
Now consider the same problem being solved by many people, or by the same person many times.

Figure 2: The same problem can be routed through many possible solution paths. Some are direct, some are circuitous, some are repeated often enough to become thicker.
The same high-dimensional problem can be solved in many ways. If I ask for a Python script to clean a spreadsheet, there are many possible routes. One person may use pandas in a clean sequence of operations. Another may write a brittle loop. A third may over-engineer the problem. A fourth may first ask for more information, discover the schema, validate edge cases, and then write a more robust solution.
From the outside, the output may look similar. There is a cleaned CSV at the end. But the route taken matters. It matters for speed, quality, code robustness to small changes and of course, it matters for whether the user understands what happened.
This is why I find the phrase "reasoning model" slightly misleading if it makes us imagine a purely internal act of reasoning. A lot of the apparent reasoning improvement may come from the accumulation and reuse of prior routes. The model is not always discovering the path from scratch. Often it is moving through a space where many others have already left traces.
This is not meant as a cynical statement. There is a real acceleration here, yet the acceleration does not come from nowhere. It comes from the fact that the world has been generating an enormous number of problem-solution traces, many of which can be embedded, compressed, evaluated, and made available for future inference.
And this is where embeddings matter in the non-technical sense, which is also why I keep returning to the idea of human embeddings. The old problem was that language and human intention are too varied to match exactly. People do not ask the same question in the same words. They use synonyms, partial descriptions, mistakes, fragments, screenshots, spreadsheets, and sometimes just vibes. But once text, documents, code, and perhaps even workflows are represented in a space where similar things sit near one another, exact wording becomes less important. The model can search in meaning space. It can say: this prompt looks like that family of prior problems; those problems tended to be solved by this kind of route.
So the system does not need to "understand" in the human sense for this to produce very powerful behavior. It needs a way to represent similarity, a way to score candidate routes, and a way to retrieve or reconstruct routes that worked before.
Evaluation Is The Compounding Engine
The next step is evaluation.
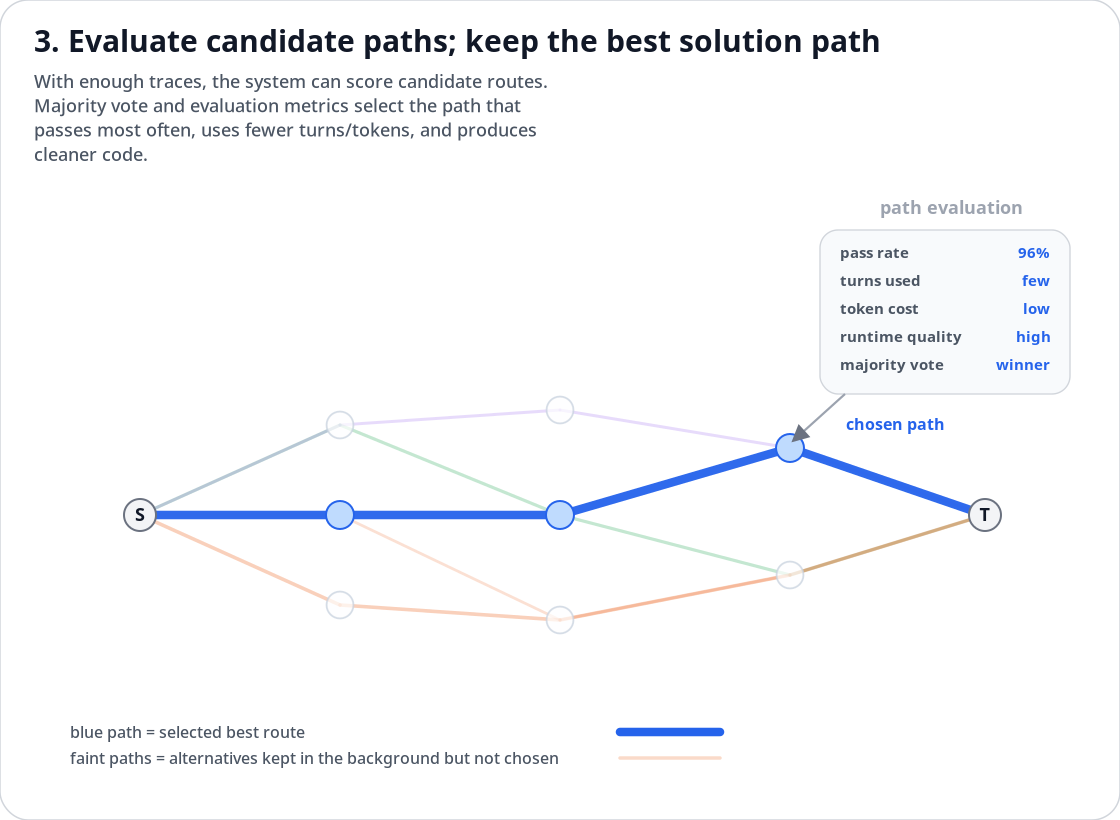
Figure 3: Candidate paths can be evaluated. The route that passes more often, uses fewer turns, costs fewer tokens, and produces cleaner outputs becomes the preferred route.
Once you have many possible solution paths, the system can begin to score them. Which route passed the tests? Which route did the user accept? Which route required fewer turns? Which route produced cleaner code? Which route avoided the common failure mode? Which route generated an output that was copied, run, saved, published, or reused?
This is not so different from how human knowledge accumulates. We try things. Some work. Some fail. Some become habits. Some become templates. Some become methods. Over time, a community develops a repertoire of moves. The difference is speed, scale, and traceability. A platform can observe millions of such moves, across millions of users, across many domains, and use them to improve future predictions.
This also means that the unit of learning is not only the artefact. It is the evaluated path. The artefact is the final code or the final text. The path is the sequence that got there. In many domains, the path is the real scarce object.
That is why the "models are just predicting the next token" line can be technically true and sociologically incomplete. Yes, there is prediction. But the object being predicted is increasingly embedded in a huge social and institutional process of path discovery. This is the same concern that sits behind the earlier reflection on AI, human cognition and knowledge collapse: humans are not only supplying language. They are supplying attempts, corrections, failures, workarounds, preferences, and signals of acceptance.
In that sense, reasoning models improve so quickly because they sit inside a feedback system. They do not merely consume a static corpus. They participate in a live economy of attempts. The more the system is used, the more it observes which routes work. The more routes it observes, the faster it can move the next user toward a plausible fixed point.
This is one reason why the experience can feel so strange. You drop in a spreadsheet, ask an imprecise question, and the system appears to know that what you really want is a script, a cleaned dataset, a chart, and perhaps a short explanation. Part of that is model capability. Part of it is intent prediction. And part of it is that many people before you have already walked very similar paths.
From Reasoning To Retrieval
This gives us the fourth picture.
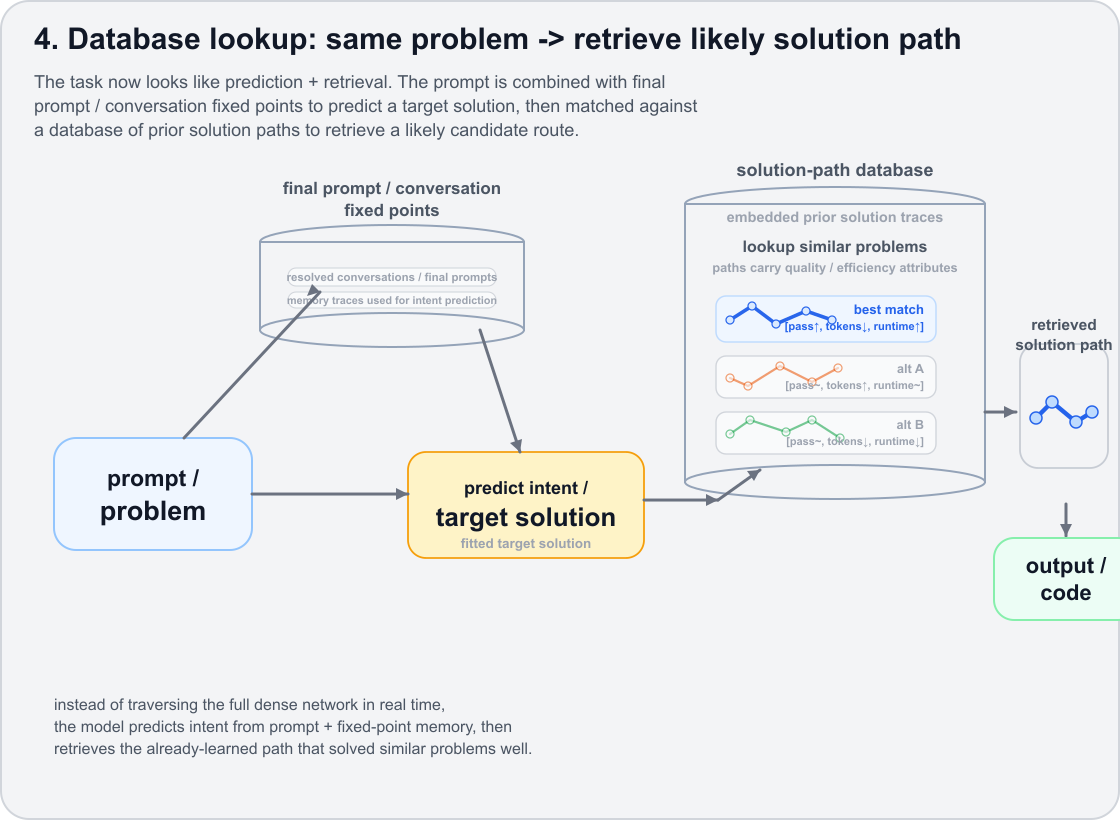
Figure 4: Once enough traces exist, the task begins to look like prediction plus retrieval. The system predicts the target solution and retrieves or reconstructs a likely route from prior solution paths.
At some point the process begins to look less like traversing the full dense network in real time and more like prediction plus retrieval. The prompt reveals intent, the LLM guesses the likely target. It searches a library of prior solution paths. It retrieves, adapts, and compresses a route that solved similar problems well before.
Again, this is a stylized picture. But it captures something important about why the frontier can move so fast. The frontier is not only the frontier of a model in isolation. It is the frontier of a model connected to a growing stock of human and machine-generated solution traces.
This is also why the most valuable data is often not generic text. It is high-quality context paired with evaluated outcomes. A random pile of text is useful up to a point. But a corpus of problems, attempts, corrections, tests, accepted solutions, domain constraints, and final outcomes is much more powerful. It contains information about how to move. This links quite naturally to the older discussion of data markets and welfare: the welfare question is not simply who has more data, but what kind of signal, matching, and extraction architecture the data enables.
That is the hidden architecture behind a lot of the current AI experience. We are not just automating output production. We are automating the reuse of paths through problem space.
Why This Changes Intellectual Property
This has fairly large implications for intellectual property, although I think the usual IP debate is too narrow.
The usual frame is: did the model copy the text, the image, the code, the song, the book, the article? That question matters. But it is not the only question. A deeper question is: what happens when a system learns the route by which many people transform a problem into a solution?
Classic IP regimes are built around artefacts. They protect a text, a design, a piece of software, a patentable invention, a recorded performance. But if a model can cheaply regenerate functionally equivalent artefacts by drawing on learned solution paths, the economic value of the artefact changes. Routine execution becomes easier to copy, imitate, or regenerate. The moat around implementation weakens.
This does not mean execution no longer matters. That would be too glib. Execution still matters where there are real-world constraints: distribution, trust, regulatory approval, physical production, organisational capacity, tacit knowledge, relationships, accountability. But for many classes of symbolic work – code, writing, analysis, design variants, workflows – the marginal cost of execution is falling very quickly.
So where does scarcity move?
It moves upstream to problem selection, framing, taste, judgement, domain context, and data. It also moves downstream to validation, trust, authority, distribution, and institutional adoption. The idea is not valuable as a disembodied slogan. The idea is valuable when it identifies the right problem, organizes the relevant context, creates a useful map of the solution space, and gives others a reason to believe that the map is worth following.
This is also the point where the earlier argument on AI and validators becomes central: if execution is cheap, the binding constraint shifts toward who can validate the claim, certify the path, and make the result socially usable.
This is why I think AI pushes us to rethink the old line that "ideas are cheap, execution is everything." That line made sense in a world where implementation was slow, costly, and institutionally difficult. It becomes less true in a world where a rough idea can be converted into a working prototype, a memo, a dataset, a chart, a literature review, or a software scaffold in minutes.
The scarce step may increasingly be knowing what to ask, why it matters, what constraints should bind the answer, what evidence would validate it, and what social purpose the output should serve.
That is a different economy of ideas.
But Should Ideas Be Owned?
The immediate temptation is to say: if ideas become more valuable, we need stronger ownership of ideas. I am not sure that follows. In fact, it may be exactly the wrong conclusion.
Ideas are not like land. They often become valuable because they circulate, collide, mutate, and are tested by others. Knowledge creation is cumulative. It depends on shared language, shared methods, shared institutions, and shared trust. If every useful conceptual move is enclosed too aggressively, the system may protect some private rents while damaging the broader process of discovery.
At the same time, pretending that there is no extraction problem is naive. If a person, a community, or an institution invests heavily in discovering a solution path, and a platform then absorbs that path into a model and sells the compressed capability back to everyone else, there is a real political-economy question. Who created the value? Who captured it? Who gets attribution? Who gets paid? Who retains authority? Who can contest the system’s use of that knowledge?
The current legal machinery is poorly suited to this. It can sometimes detect copying of an artefact. It is much worse at dealing with embedded know-how, collectively produced path libraries, and the reuse of functional patterns learned across many interactions. We do not really have an attribution system for solution-path reuse. We do not have a social contract for the extraction of reasoning traces.
This is where the IP debate should probably move: less toward a fantasy of owning every idea, and more toward governance of data provenance, training rights, path reuse, attribution, collective licensing, auditability, and contestability. The point is not only to protect creators from copying. It is to prevent the enclosure of the knowledge infrastructure itself. In that sense, the IP question is also part of the broader problem of fragility and global governance: who owns the infrastructure through which claims are made, checked, transmitted, and acted upon?
The Narcissism Problem
There is a more uncomfortable social layer here.
We already live in a world in which a lot of idea-sharing is performative. Social media rewards visibility, not necessarily truth. Academia rewards citations, status, and positional goods, not always cumulative understanding. Politics rewards narrative dominance. Platforms reward engagement. This is very close to the argument in Attention Markets, Reward Curvature, and the Case for De-Weaponizing the Information Sphere: once the reward schedule to visibility becomes convex, people overinvest in whatever travels. In all of these settings, there is a selection pressure toward people who are willing to perform themselves, their ideas, and their certainty.
AI interacts with that in two opposite ways.
On the one hand, it may reduce the value of performance. If execution becomes cheap, the person who merely performs expertise without generating useful problem frames may be easier to expose. If everyone can produce polished text, polish itself becomes less informative. The narcissistic performance of productivity – the thread, the deck, the hot take, the "look what I built" demo – may become less scarce.
On the other hand, AI may supercharge the same performance economy. It allows people to produce more output, faster, with greater confidence and fewer frictions. It can flood the zone with plausible claims. It can make weak ideas look finished. It can allow authority to be simulated. This is the synthetic authority problem, and it connects directly to the earlier note on narratives and validators: if the model can produce a polished answer and the platform can make it visible, the social system may allocate attention to what appears fluent rather than to what is valid.
That is why validation becomes the central bottleneck. Not content creation. Validation.
The danger is not only that people will cheat, plagiarize, or automate low-quality work. The deeper danger is that the social reward system may become even more detached from actual knowledge creation. We may get a world of infinite execution and scarce judgement. Infinite text and scarce validation. Infinite claims and scarce trust.
In that world, the old academic or professional instinct – "do not share too early, someone may steal the idea" – becomes both more understandable and more damaging. It is understandable because solution paths can be absorbed and reused. It is damaging because if high-trust knowledge sharing collapses, the whole system loses the cooperative search process that makes ideas better in the first place.
This is the tension I keep coming back to. We need more sharing to solve hard problems. But we need sharing architectures that do not simply turn every shared trace into platform-owned capability and every public idea into material for someone else’s performance game.
What Would A Better Equilibrium Look Like?
The better equilibrium is not simply stronger IP. Nor is it a naive open commons in which all extraction is ignored. It is something more institutional.
First, we need better provenance. People and institutions should be able to know which corpora, data, workflows, and knowledge graphs sit behind systems that make consequential claims. This does not mean every model output needs a fake footnote. It means the training and retrieval stack should be more contestable.
Second, we need better attribution norms for ideas and paths, not only for artefacts. If a model or organisation is drawing on a community’s accumulated solution traces, there should be ways to recognize that contribution, compensate it where appropriate, and prevent one-sided enclosure.
Third, we need public or community stewardship of important knowledge infrastructures. If solution-path libraries become a core input into science, law, public administration, education, and policy, then leaving them entirely inside private platforms is a governance choice. It is not a neutral market outcome.
Fourth, we need to reward problem framing and validation more explicitly. In many domains, the person who asks the right question, builds the right dataset, defines the right evaluation metric, or notices the hidden failure mode is creating more value than the person who produces the final surface artefact. Our institutions are still bad at recognizing this.
Finally, we need to be honest about the social psychology of the system. If attention markets reward narcissistic performance, then AI will not automatically create a wiser public sphere. It may just make performance cheaper. This is also why the earlier post on research topologies and AI matters here: the topology of who produces, validates, amplifies, and receives status is not peripheral. It is the system. The policy question is therefore not only how to regulate copying. It is how to build institutions that reward useful contribution, careful validation, and genuine knowledge transmission.
The Design Question
The reason I find the solution-path framing useful is that it connects several debates that are usually kept separate.
It explains why reasoning models can improve so quickly: they are learning from evaluated traces through problem space. It explains why execution moats are eroding: many symbolic artefacts can be regenerated once the path is known. It explains why ideas, data, context, and authority become more valuable: they define which paths matter and whether a proposed solution should be trusted. It also explains why the current information environment feels so unstable: the same machinery that accelerates useful work can also accelerate performative output and synthetic authority.
The question, then, is not whether AI will make us more productive. In many domains it obviously will. The deeper question is what kind of knowledge economy we are building around that productivity.
Are we building a system in which shared reasoning traces become an auditable commons that improves collective problem-solving? Or are we building a system in which traces are extracted, enclosed, and converted into private authority by a small number of platforms?
That, to me, is the real IP question. Not just who owns the artefact, but who governs the path.
Related Reading
- Discussion of AI, Human Cognition and Knowledge Collapse – closest companion piece on cognition, knowledge transmission, and AI-mediated fixed points.
- Human embeddings – background for the embedding-space intuition used in the middle of this post.
- On research topologies, AI, the potential threat to the enlightenment consensus and rebalancing of power – connects solution-path reuse to the institutional topology of knowledge production.
- Thoughts on narratives and the role of AI and validators going forward – the validator-layer argument behind the discussion of synthetic authority.
- Attention Markets, Reward Curvature, and the Case for De-Weaponizing the Information Sphere – companion post on why performative output can dominate validation in attention markets.
- Fragility and the State of Global Governance – broader governance frame for the institutional stakes.
- Data Markets and Welfare – useful background on why data, signals, and extraction architecture become central assets.